Browse categories
Explore
Fiverr Pro
English
$
USD
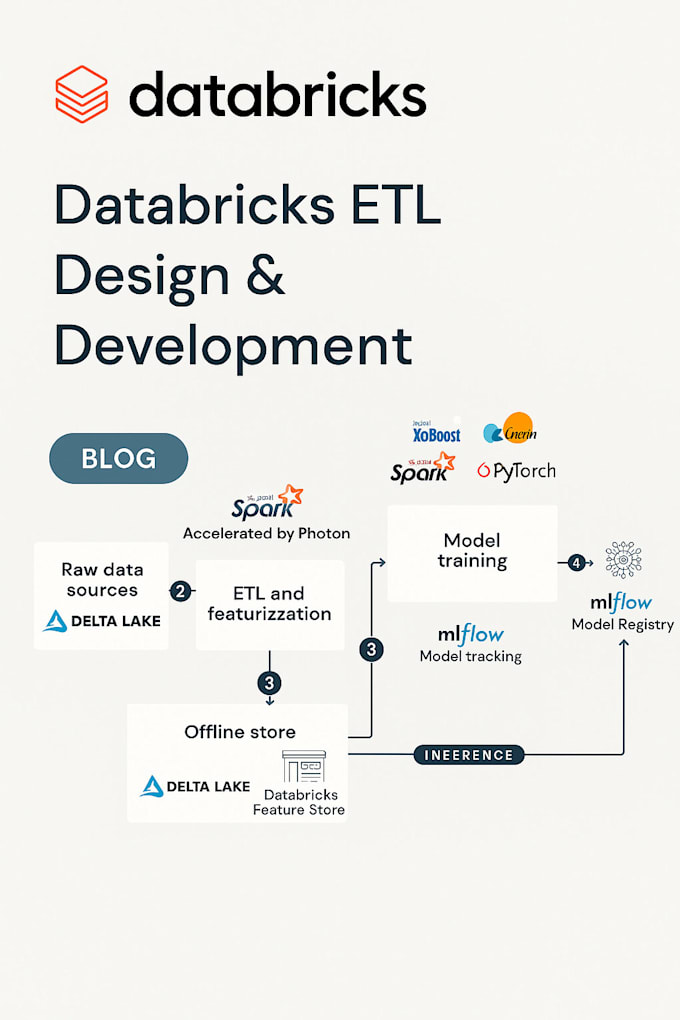
Need to process large datasets efficiently? Want a robust, scalable data pipeline built on Azure Databricks?
As a Data Engineer with 3+ years of experience, I will design, develop, and optimize end-to-end data pipelines using Azure Databricks, PySpark, and Delta Lake fully integrated with your cloud ecosystem.
What I Offer:



What do you need from me to get started
Please share the source system details, data format, business logic, and target destination (e.g., Blob, SQL DB, ADLS)
Will you deploy the pipeline into my Azure environment
I’ll provide code and detailed deployment instructions. Hands-on deployment available as a custom offer
Can you integrate this with Azure Data Factory
Yes! I can orchestrate the Databricks job via ADF if needed — mention it in your requirements
Is this suitable for production workloads
Absolutely — Premium package includes scalable, production-grade pipeline architecture with modular notebook design and data modeling.