Browse categories
Explore
Fiverr Pro
English
$
USD
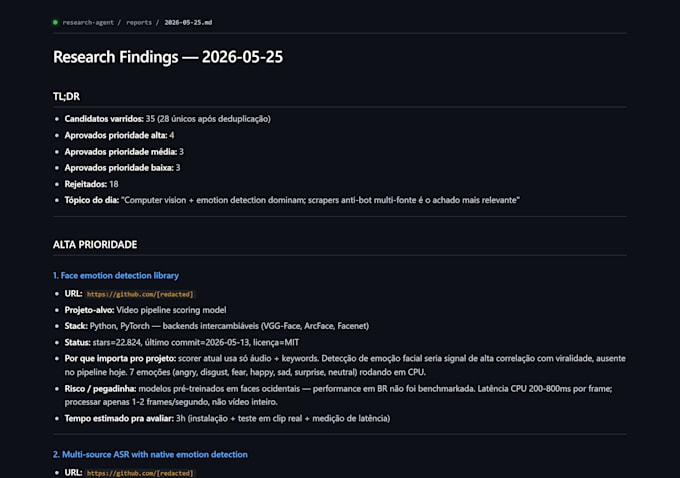
Engineer, beta reader and translator EN to PT, fast and reliable
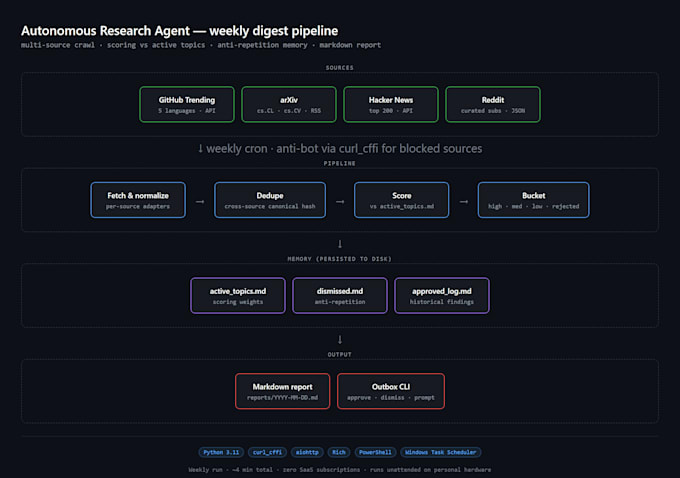
Most scraping gigs on Fiverr break the moment a site enables Cloudflare Bot Management or DataDome. I write scrapers that DON'T.
Stack I use:
Targets I have successfully scraped:
What I deliver:
Legal note: scraping is YOUR responsibility. I build the tool; you ensure compliance with ToS, robots.txt, and your jurisdiction's laws.


Technology:
Python
•
Scrapy
•
Selenium
•
Beautiful soup
•
Playwright
Technique:
Automated
Will this scraper work forever?
No. Anti-bot defenses evolve. Scrapers break every 3-12 months. I document HOW the bypass works so YOU can adapt - or hire me for patches.
Do you provide proxies?
No. You buy proxies (recommend Decodo or BrightData residential - $5-8/GB). I configure the rotation logic in the scraper.
Can you scrape Instagram / Facebook / LinkedIn?
No. Those have aggressive legal teams and active enforcement. I decline these requests. Other anti-bot sites are fine.