Run LLaMA models locally on your own hardware and unlock fast, private AI! I specialize in deploying LLaMA LLMs for beginners and developers using llama.cpp, a lightweight C/C++ inference engine that enables high-performance local inference. Youll get a full setup on Windows, and Linux. no cloud, no recurring fees, and full control over your AI models.
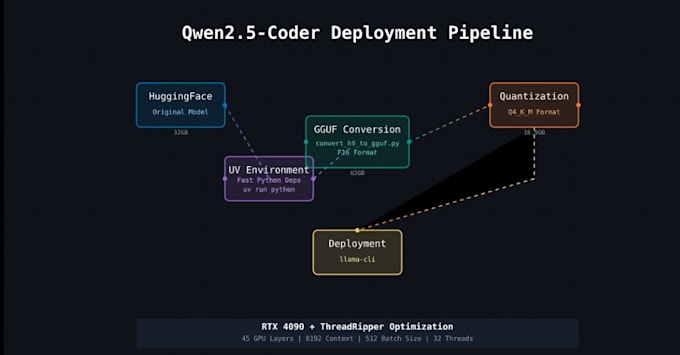
- Local Installation: Ill install and configure the latest LLaMA (2/3) or compatible GGUF models on your machine. Whether youre on Windows, Linux, or Mac, I handle environment setup, dependencies, and llama.cpp build or binary installationmedium.com
- GPU & CUDA Optimization: With NVIDIA CUDA support, Ill enable GPU acceleration (and multi-threading) to speed up inference. Using llama.cpps optimizations and model quantization (4-bit/8-bit), well reduce memory usage so even large models run smoothly(Quantized models are much lighter while keeping good accuracy)
- Fine-Tuning & Custom Data: In the Premium package, I fine-tune your LLaMA model on your own dataset using LoRA adapters (LoRA lets us adapt the model to your needs by training only the adapter weights)