Browse categories
Explore
Fiverr Pro
English
$
USD
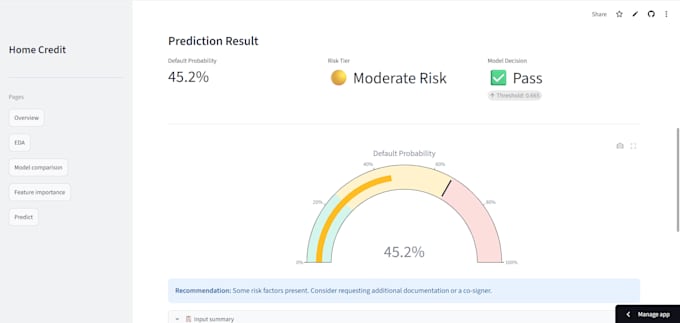
Live Demo: credit-risk-prediction-better.streamlit.app
GitHub: github.com/Niqar/Credit-risk-prediction
Are you sitting on raw data but don't know how to turn it into a working ML model? I'll build you a complete, production-ready machine learning pipeline from messy data to a model that actually performs.
What I'll deliver:
Data cleaning & feature engineering (handle missing values, encoding, scaling)
Model training LightGBM, XGBoost, Random Forest, or Logistic Regression
Hyperparameter tuning with Optuna for best performance
Full evaluation report (AUC, F1-score, Precision, Recall, Confusion Matrix)
Clean scikit-learn Pipeline reproducible & ready to deploy
Jupyter Notebook + documented Python code
GitHub repository (on request)
Why work with me:
I don't just train a model and hand it over. I document every step so you understand what was done and why and I make sure the pipeline is clean enough to reuse or extend.
Check my portfolio: credit-risk-prediction-better.streamlit.app
Feel free to message me before ordering I'll review your dataset and confirm I can help.



Programming language:
Python
•
SQL
Frameworks:
Scikit-learn
•
Keras
•
PyTorch
Tools:
Jupyter Notebook
•
OpenCV
•
TensorFlow
•
Excel
•
Colab
What type of data do you work with?
I work with structured/tabular data — CSV, Excel, or SQL exports. This covers classification problems (fraud, churn, credit risk) and regression problems (price prediction, sales forecasting). For image or text data, please message me first so I can assess the scope.
What if my dataset is messy or has missing values?
That's completely normal — handling messy data is part of what I do. I'll clean it, handle missing values, encode categorical features, and scale numerical ones as part of every package.
Which machine learning models do you use?
Mainly LightGBM, XGBoost, Random Forest, and Logistic Regression — depending on your data and goal. In the Standard and Premium packages I train and compare multiple models so you get the best-performing one.
Will I be able to reuse or modify the code myself?
Yes. All code is clean, commented, and structured as a proper scikit-learn Pipeline — so it's easy to retrain with new data or adjust parameters. I'll also explain the key parts so you're not left guessing.