Browse categories
Explore
Fiverr Pro
English
$
USD





Tired of manual document processing? Let AI do it in seconds.
I will build a custom OCR and Document Intelligence pipeline that extracts, processes, and analyzes text from PDFs, scanned files, handwritten sheets, and images delivering clean, structured, production-ready output.
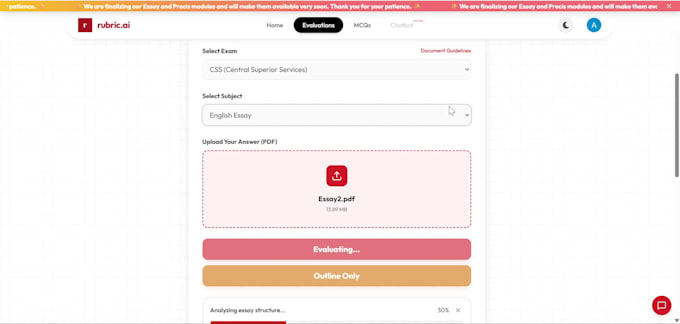
I've built and deployed real OCR systems like Rubric Ai including an AI-powered exam evaluation platform and an automated invoice processing pipeline production systems with real users, not side projects.
What I Build: OCR pipeline for PDFs, images & scanned documents Preprocessing for noisy, handwritten & low-quality inputs LLM-powered analysis & intelligent text extraction Automated annotation & evaluation engine Structured JSON/CSV output ready for integration FastAPI backend & database integration
Perfect For: Legal, medical & financial document processing Exam, assessment & grading automation Invoice, receipt & contract data extraction
Why Choose Me: Real deployed OCR systems not just tutorials Handles handwriting, mixed languages & poor scans Clean code, full source included, on-time delivery
Message me and let's scope your project before you order.
Ai and Computer vision Solutions
Languages
Can you build a custom document evaluation or grading system?
Absolutely. I've built rubric-based LLM evaluation engines that score and annotate documents section by section. Whether it's exam grading, contract review, or form validation I can build an intelligent evaluation pipeline tailored to your criteria.
What types of documents can your OCR pipeline process?
My OCR pipeline handles PDFs, scanned images, photographed documents, and handwritten sheets. It works with low-quality scans, mixed-language content, and noisy inputs preprocessing is included to ensure clean, accurate text extraction every time.
Can you integrate the OCR system with my existing application or database?
Yes. I build FastAPI REST backends that connect directly to your existing application. I support MongoDB and PostgreSQL for structured data storage and can deliver clean JSON or CSV output compatible with any downstream system.
What is document intelligence and how is it different from basic OCR?
Basic OCR just extracts text. Document intelligence goes further — using LLMs to analyze, classify, annotate, and evaluate the extracted content against defined criteria. It's the difference between reading a document and actually understanding it.
Do you provide source code and documentation?
Yes, every delivery includes full source code, detailed inline comments, and setup documentation so your team can maintain and extend the system independently without any dependency on me.
How long does it take to build a complete document intelligence pipeline?
A basic OCR extraction pipeline takes 3 days. A full document intelligence system with LLM analysis, annotation engine, API, and database integration typically takes 7-10 days depending on complexity. Message me first to get an accurate timeline for your project.