Browse categories
Explore
Fiverr Pro
English
$
USD
Systems and ML Projects C Python SQL On Time and Optimized
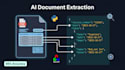
Are you drowning in PDFs, invoices, forms, or scanned images that need data extracted from them? I build production-ready AI systems that do it automatically.
I am an AI and computer vision engineer with hands-on experience building end-to-end deep learning pipelines from raw data all the way to a working, deployable solution you can actually use.
WHAT I BUILD
Intelligent Document Processing (IDP)
Extract structured data from invoices, receipts, contracts, medical forms, tax documents, and any custom PDF or image format.
Custom OCR Pipelines
Beyond basic OCR, I build AI systems that understand layout, tables, checkboxes, and handwriting using TesseractOCR, PaddleOCR, and deep learning.
️ Computer Vision & Object Detection
Custom YOLO (v8/v11) models, image classification, segmentation, and object tracking trained on your own dataset.
AI/ML Model Development
CNN, RNN, LSTM for classification, regression, NLP text extraction, and time-series forecasting.
Model Deployment & API
REST API via FastAPI or Flask, Docker containerization, cloud deployment (AWS, GCP), integration with your frontend.
TOOLS & STACK
Python, PyTorch, TensorFlow, OpenCV, YOLO, PaddleOCR, Tesseract

Do I need to provide training data?
It depends on the project. For common document types like invoices or receipts, I can use pre-trained models and adapt them to your format. For highly custom documents or proprietary layouts, a sample dataset of 50–200 examples is ideal. If you do not have one, I can guide you on how to collect and
What format will the extracted data be delivered in?
By default I deliver structured JSON or CSV output. If you need it in a database, Excel file, or piped into your existing system via API, that can be arranged — just mention it when you message me.
How accurate will the extraction be?
Accuracy depends on document quality and complexity. For clean, digital PDFs it typically reaches 95–99%. For scanned or handwritten documents, 85–95% is realistic. I always test on your actual documents before delivery and include a performance report.
Can you work with documents in languages other than English?
Yes. PaddleOCR supports 80+ languages and I have experience with multilingual pipelines. Please mention your language when you contact me.
Will I own the code?
Yes, 100%. All source code, model weights, and documentation are yours. I do not retain any rights to what I build for you.


