Browse categories
Explore
Fiverr Pro
English
$
USD
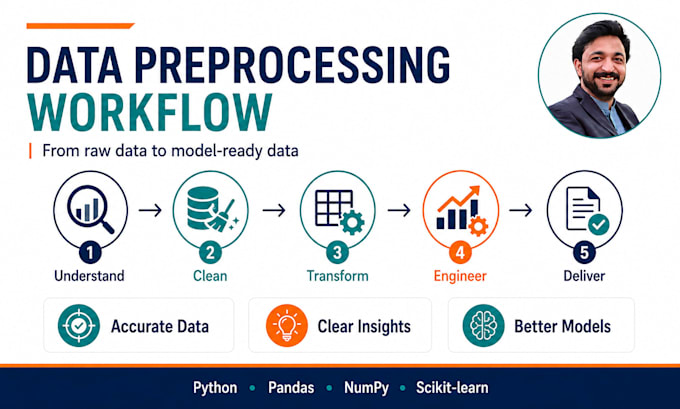
Are you working with messy, incomplete, unstructured, or raw data that needs to be prepared for machine learning, research, or business analysis? I will clean, preprocess, transform, and engineer your dataset into an AI-ready format using Python and industry-standard tools.
My services include:
You will receive clean structured data, reusable Python code, and clear documentation depending on your package.
Please contact me before placing an order so I can review your dataset, goals, file format, and project requirements.



Programming language:
Python
•
SQL
•
Colab
•
NoSQL
•
MLflow
Frameworks:
Scikit-learn
•
SimpleCV
•
Keras
•
PyTorch
•
Panda
Tools:
Jupyter Notebook
•
OpenCV
•
TensorFlow
•
SimpleCV
•
CVAT
•
Colab
What type of datasets can you clean and preprocess?
I can work with CSV, Excel, structured tables, research datasets, business data, healthcare data, survey data, forecasting data, and machine learning datasets.
What will you do in data preprocessing?
I can handle missing values, duplicates, outliers, invalid records, inconsistent formatting, encoding, scaling, normalization, standardization, and data transformation.
Do you provide feature engineering?
Yes. I can create new meaningful features, select important features, reduce unnecessary features, and prepare the dataset for machine learning models.
Will I receive the source code?
Yes, depending on the package. I can provide clean and reusable Python code using tools like Pandas, NumPy, Scikit-learn, and Jupyter Notebook.
Can you perform Exploratory Data Analysis?
Yes. I can provide EDA including summary statistics, distribution analysis, correlation analysis, visualizations, and key insights from your dataset.
Can you prepare data for machine learning models?
Yes. I can prepare an AI-ready dataset suitable for classification, regression, clustering, forecasting, or deep learning projects.
Do you work on research or thesis datasets?
Yes. I can help with thesis, publication, academic, healthcare, EEG/BCI, and research-level dataset preparation.
Q8: What do you need from me before starting?
Please share your dataset, project goal, target column if available, required output format, and any specific preprocessing or feature engineering requirements.
Q9: Can you build a machine learning model in this gig?
This gig mainly focuses on data preprocessing and feature engineering. If you need model development, I can offer it as an extra service or through a separate ML gig.
Q10: Should I contact you before placing an order?
Yes, please contact me first so I can review your dataset, understand your requirements, and recommend the best package.