Browse categories
Explore
Fiverr Pro
English
$
USD
SKILLED FREELANCER COMMITTED TO QUALITY CONTENTS
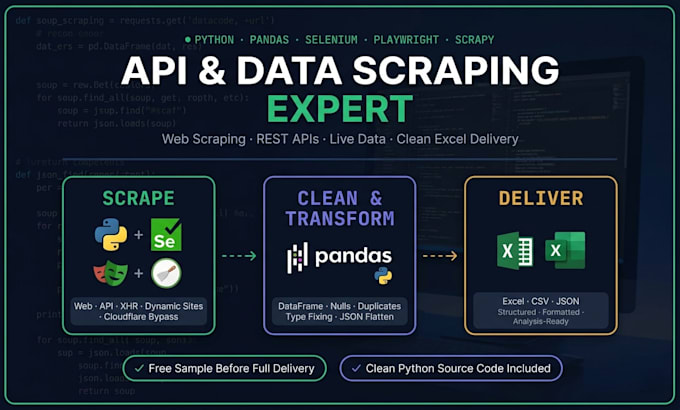
I Will scrape dynamic websites and api endpoints.
Need data from any website, hidden API, or live feed structured, cleaned, and ready to use? You're in the right place.
I handle both dynamic web scraping and API endpoint extraction from JavaScript-rendered pages to reverse-engineered XHR/Fetch APIs then deliver everything through a full Pandas cleaning and formatting pipeline.
WHAT YOU GET:
Dynamic website scraping
API endpoint discovery & reverse engineering (XHR/Fetch)
REST API scraping tokens, auth headers, session handling
Cloudflare, Turnstile & anti-bot bypass
Real-time data sports scores, crypto, prices, listings
Nested JSON flattened into structured sheets
Excel / CSV / JSON output
️ STACK:
Python · Pandas · Selenium · Playwright · Scrapy · Requests · BeautifulSoup · openpyxl
WHY ME :
Both web scraping AND API extraction one seller, full coverage
Free sample before full delivery
Reusable Python script included with every order
No raw dumps cleaned, typed, formatted files only
Turnstile & Cloudflare specialist
Message me first feasibility check, no obligation.


 (1)_kv3che.jpg)
 (1)_h3ydiz.jpg)
Technology:
Python
•
Excel
•
Selenium
•
Beautiful soup
•
Pandas
Information type:
Websites
Technique:
Automated
Q1: What's the difference between web scraping and API scraping?
Web scraping extracts data directly from a website's HTML — useful for pages without a public API. API scraping intercepts the hidden backend calls a site makes (XHR/Fetch requests) to pull cleaner, faster, more reliable data. I do both — whichever gives you the best result for your specific site.
Q2: Can you scrape JavaScript-rendered or dynamic websites?
Yes. I use Selenium and Playwright to fully render JavaScript pages, handle infinite scroll, lazy loading, and AJAX-based content before extracting any data — so nothing gets missed.
Q3: Can you bypass Cloudflare or Turnstile protection?
Yes. I have hands-on experience capturing Cloudflare Turnstile tokens including scroll-triggered and user-agent-based challenges — one of the most complex bot-protection systems currently in use. Message me with your target site for a free feasibility check.
Q4: What does "data cleaning and formatting" actually mean?
Before delivery, every dataset goes through a full Pandas pipeline: null values handled, duplicates removed, data types corrected, column names standardized, nested JSON flattened, and Excel formatted with proper headers and column widths. You receive a finished, professional file — not a raw dump.
Q5: Will I receive the Python script?
Yes — every order includes clean, commented, reusable Python source code so you can re-run the scraper yourself anytime without hiring again.
Q6: What output formats do you deliver?
Excel (.xlsx), CSV, and JSON by default. Google Sheets delivery available on request. Just mention your preference before ordering.
Q7: Is web scraping legal?
I only work with publicly accessible data and do not scrape sites that explicitly prohibit it in their Terms of Service. I never extract private user data or bypass paywalls. Message me with your target URL before ordering so I can confirm feasibility and compliance.
Q8: How do I get started?
Message me before placing an order. Share your target URL, the data fields you need, and approximate volume. I'll confirm feasibility, timeline, and any technical challenges — completely free, no obligation